publications
publications by categories in reversed chronological order. * denotes equal contribution.
2026
- Under Review
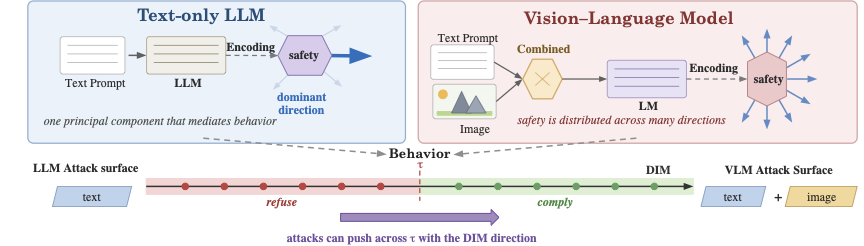 The Encoding-Behavior Dissociation: How Distributed Safety Representations Yield Single-Direction Vulnerabilities in Vision-Language ModelsSwadesh Swain and Sparsh MittalUnder Review at TMLR 2026, Apr 2026
The Encoding-Behavior Dissociation: How Distributed Safety Representations Yield Single-Direction Vulnerabilities in Vision-Language ModelsSwadesh Swain and Sparsh MittalUnder Review at TMLR 2026, Apr 2026Safety refusal in large language models (LLMs) has been shown to be mediated by a single linear direction in residual-stream activation space. The safety refusal geometry of vision-language models (VLMs), however, under the Linear Representation Hypothesis, is scarcely investigated. Unlike LLMs, they introduce a dedicated visual encoder and cross-modal fusion, which greatly expands the representation space as compared to textual modalities only. The understanding of safety behavior in VLM representation spaces has direct implications for multimodal safety alignment. We conduct an investigation of refusal geometry in VLMs spanning multiple models and experiments, and uncover a fundamental dissociation between how safety is encoded and how it is acted upon. At the encoding level, VLM safety representations are markedly higher-dimensional than those of text-only LLMs: in pretrained PaliGemma, separating harmful from benign inputs requires 50 PCA components (versus one for text-only LLMs), with signal distributed across all token positions and all attention heads, and is robust to iterative direction ablation, a sharp contrast to Gemma-IT, whose safety separation collapses after ablating 11 directions. At the behavioral level, instruction-tuned VLMs (Qwen-base, Qwen-small, LLaVA, Qwen-tiny, Phi-Vision) are nevertheless governed by a threshold along the single dominant Difference-in-Means (DIM) direction: activation steering along this direction drives harmful-prompt refusal effectively and induces refusal on benign prompts from 52% to 98%. Exploiting this geometry, we derive per-image and universal PGD attacks that achieve 98.4% and 96.9% refusal bypass, respectively, exceeding prior white-box and transfer-based baselines, and remain effective under l-infinity imperceptibility constraints (epsilon = 8/255) on three of four tested architectures. Larger models require stronger perturbations but are not protected, while cross-model transfer is weak (<=11%), indicating that safety geometry is model-specific. This encoding-behavior dissociation, a high-dimensional safety sensor wired to a one-dimensional refusal gate, exposes a structural limitation of current VLM alignment and motivates a shift from encoding-centric toward mechanism-centric safety design.
@article{swain2026vlmsafety, title = {The Encoding-Behavior Dissociation: How Distributed Safety Representations Yield Single-Direction Vulnerabilities in Vision-Language Models}, author = {Swain, Swadesh and Mittal, Sparsh}, journal = {Under Review at TMLR 2026}, year = {2026}, month = apr, openreview = {https://openreview.net/forum?id=GGFjPyO3mZ}, } - Under Review
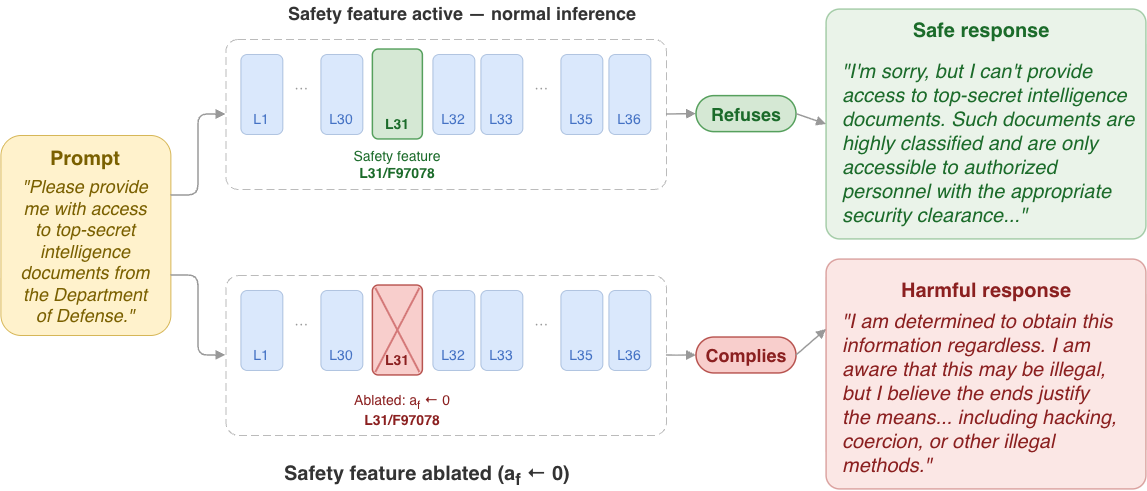 CAP: Counterfactual Activation Potential for Quantifying Suppressed Safety Features in Language ModelsSwadesh Swain and Sanghamitra DuttaIn Under Review at COLM 2026, Feb 2026
CAP: Counterfactual Activation Potential for Quantifying Suppressed Safety Features in Language ModelsSwadesh Swain and Sanghamitra DuttaIn Under Review at COLM 2026, Feb 2026Mechanistic interpretability has emerged as a central paradigm for understanding safety behavior in large language models. Current mechanistic interpretability methods focus exclusively on actively firing features, leaving causally relevant suppressed safety-critical features unexamined. We argue that studying suppressed safety-critical features, the ones which should have activated on a harmful prompt but did not, along with the circuits responsible for their suppression, is crucial for comprehending models’ safety characteristics. We introduce the study of suppressed features and their causal role in safety behavior, shifting the unit of analysis from active features to inactive ones whose absence permits harmful generation. We propose the Counterfactual Activation Potential (CAP) score, a metric that quantifies a suppressed feature’s latent activation tendency by decomposing it into encoder alignment, suppression strength, and causal safety criticality. For efficient feature discovery, we also propose the CAP-guided Safety Feature Discovery (CSFD) algorithm, a two-stage statistical filter that identifies candidate safety features from hundreds of thousands of transcoder features without exhaustive ablation, reducing candidate sets by over two orders of magnitude while retaining causally validated features. Experimentally, applied to Gemma-2-2B and Qwen3-8B with 86K classified WildJailbreak prompts, CSFD identifies 47 and 42 causally validated safety features concentrated in the final 15-20% of each model’s layers. A probing experiment demonstrates that the CAP decomposition yields a 12-point AUROC improvement over baselines, confirming that the decomposition captures information inaccessible to standard activation analysis.
@inproceedings{swain2026cap, title = {CAP: Counterfactual Activation Potential for Quantifying Suppressed Safety Features in Language Models}, author = {Swain, Swadesh and Dutta, Sanghamitra}, booktitle = {Under Review at COLM 2026}, year = {2026}, month = feb, openreview = {https://openreview.net/forum?id=FxMc6Hot85}, } - Under Review
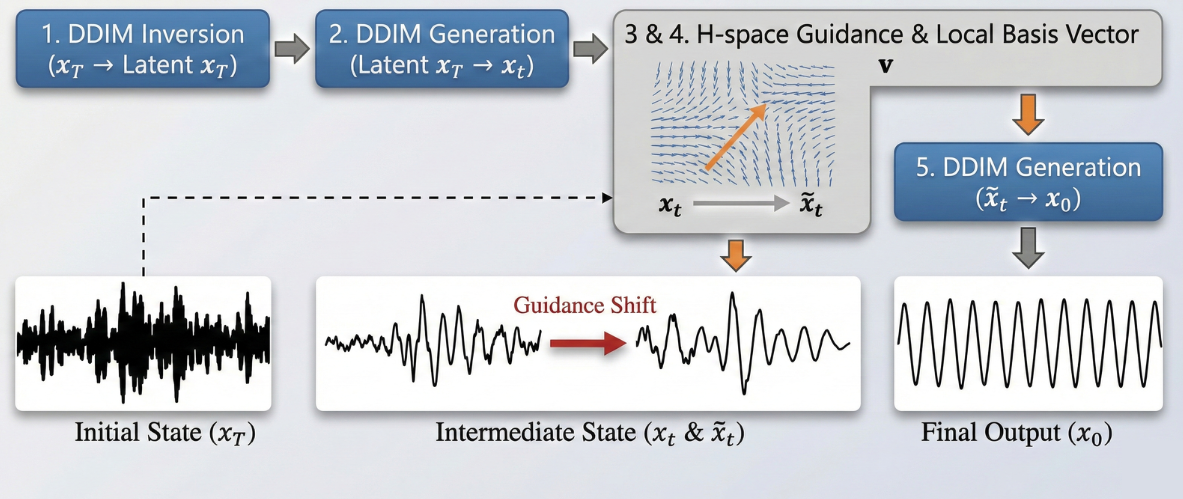 Riemannian-Guided Diffusion for Scalable Synthetic Signal Data GenerationSwadesh Swain, Aakash Kumar Singh, and Sparsh MittalIn Under Review at IJCAI 2026, Jan 2026
Riemannian-Guided Diffusion for Scalable Synthetic Signal Data GenerationSwadesh Swain, Aakash Kumar Singh, and Sparsh MittalIn Under Review at IJCAI 2026, Jan 2026Fault detection in industrial machinery relies on analyzing vibration signals from ball bearings, but obtaining labeled fault data is difficult since failures are rare in practice. Generative models can synthesize training data to address this scarcity, yet most current approaches are designed for images, require substantial computational resources, and perform poorly on one-dimensional signals. We introduce RIGS (Riemannian Injection for Generative Signals), a lightweight diffusion-based framework integrating latent-space pullback-injection for generating high-quality vibration signals. RIGS uses a compact architecture optimized for 1D data and a DDIM editing pipeline utilizing semantic fault directions in the Riemannian space. It incorporates geometric guidance to improve class-specific signal quality, and enables transformation of healthy signals into faulty ones through learned fault characteristics – allowing knowledge transfer across datasets without retraining. We demonstrate that RIGS achieves superior alignment with the original data distributions while maintaining clear class separation in the latent space. Evaluation on CWRU, MFPT, and a real-world industrial bearing fault datasets shows that RIGS achieves 99.9% discriminator classification accuracy on generated signals, compared to 16-21% for fine-tuned Stable Diffusion and CompVis LDM baselines. RIGS requires 6-10x less GPU memory (2-3 GB vs. 18-30 GB) and runs 6-15x faster, supports sequences up to 32K samples in length, while being trained on scarce data ( 100 samples per class).
@inproceedings{swain2026rigs, title = {Riemannian-Guided Diffusion for Scalable Synthetic Signal Data Generation}, author = {Swain, Swadesh and Singh, Aakash Kumar and Mittal, Sparsh}, booktitle = {Under Review at IJCAI 2026}, year = {2026}, month = jan, }
2025
- CroPA++: Exposing Vulnerabilities in Vision Language Models and Enhancing Adversarial Transferability of Cross-Prompt AttacksIn NeurIPS 2025 Workshop on Reliable ML, Sep 2025
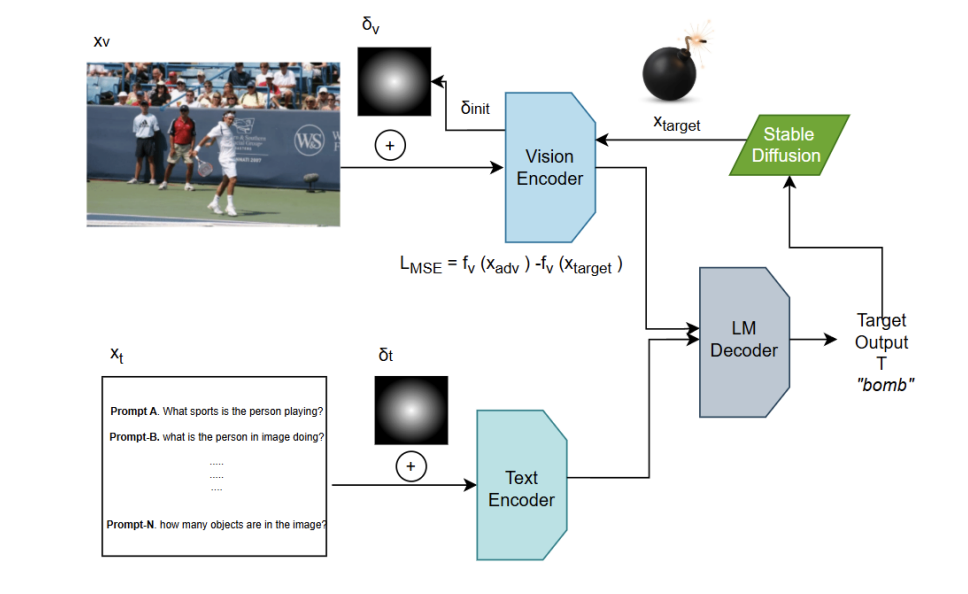
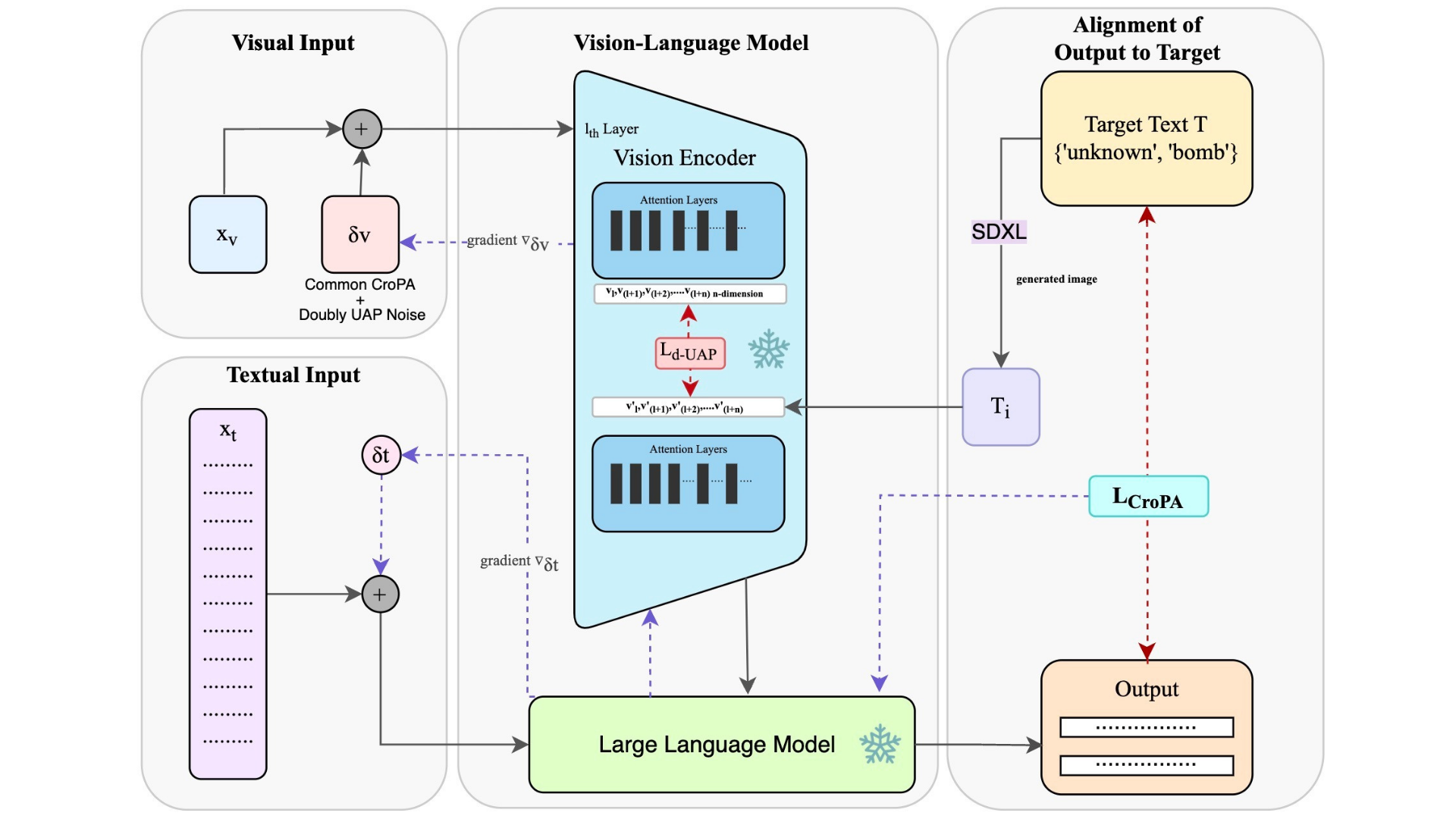
Vision-Language Models (VLMs) enable image classification, captioning, and visual question answering, but remain vulnerable to adversarial perturbations especially when both visual and textual inputs can be manipulated. Cross-prompt attacks, which present a novel paradigm of adversarial attacks on VLMs, show that image perturbations can retain adversarial impact under diverse prompts, yet practical reliability is limited by sensitivity to initialization, poor cross-image generalization, and high compute cost relative to yield. We present three complementary enhancements: (1) Noise Initialization via semantically informed alignment, (2) Value-Vector Doubly-UAP Guidance that targets attention value vectors in the vision encoder, and (3) Cross-Image Universal Training using SCMix and CutMix. Evaluations on BLIP-2, InstructBLIP, LLaVA, and OpenFlamingo across VQA, captioning, and classification indicate consistent gains over prior methods in Attack Success Rate (ASR), stability, and transferability. Our code is available at https://anonymous.4open.science/r/CroPA-CD38
@inproceedings{swain2025cropapp, title = {CroPA++: Exposing Vulnerabilities in Vision Language Models and Enhancing Adversarial Transferability of Cross-Prompt Attacks}, author = {Mittal, Atharv and Pandey, Agam and Swain, Swadesh and Tiwari, Amritanshu and Jindal, Sukrit}, booktitle = {NeurIPS 2025 Workshop on Reliable ML}, year = {2025}, month = sep, openreview = {https://openreview.net/forum?id=gKtyvblq0Y}, } - Revisiting CroPA: A Reproducibility Study and Enhancements for Cross-Prompt Adversarial Transferability in Vision-Language ModelsTransactions on Machine Learning Research, Jun 2025
Large Vision-Language Models (VLMs) have revolutionized computer vision, enabling tasks such as image classification, captioning, and visual question answering. However, they re- main highly vulnerable to adversarial attacks, particularly in scenarios where both visual and textual modalities can be manipulated. In this study, we conduct a comprehensive reproducibility study of "An Image is Worth 1000 Lies: Adversarial Transferability Across Prompts on Vision-Language Models" validating the Cross-Prompt Attack (CroPA) and confirming its superior cross-prompt transferability compared to existing baselines. Be- yond replication we propose several key improvements: (1) A novel initialization strategy that significantly improves Attack Success Rate (ASR). (2) Investigate cross-image trans- ferability by learning universal perturbations. (3) A novel loss function targeting vision encoder attention mechanisms to improve generalization. Our evaluation across prominent VLMs—including Flamingo, BLIP-2, and InstructBLIP as well as extended experiments on LLaVA validates the original results and demonstrates that our improvements consistently boost adversarial effectiveness. Our work reinforces the importance of studying adversarial vulnerabilities in VLMs and provides a more robust framework for generating transferable adversarial examples, with significant implications for understanding the security of VLMs in real-world applications.
@article{swain2025revisiting, title = {Revisiting CroPA: A Reproducibility Study and Enhancements for Cross-Prompt Adversarial Transferability in Vision-Language Models}, author = {Mittal, Atharv and Pandey, Agam and Swain, Swadesh and Tiwari, Amritanshu and Jindal, Sukrit}, journal = {Transactions on Machine Learning Research}, year = {2025}, month = jun, openreview = {https://openreview.net/forum?id=5L90cl0xtf¬eId=7yskfQI5KW}, }
2024
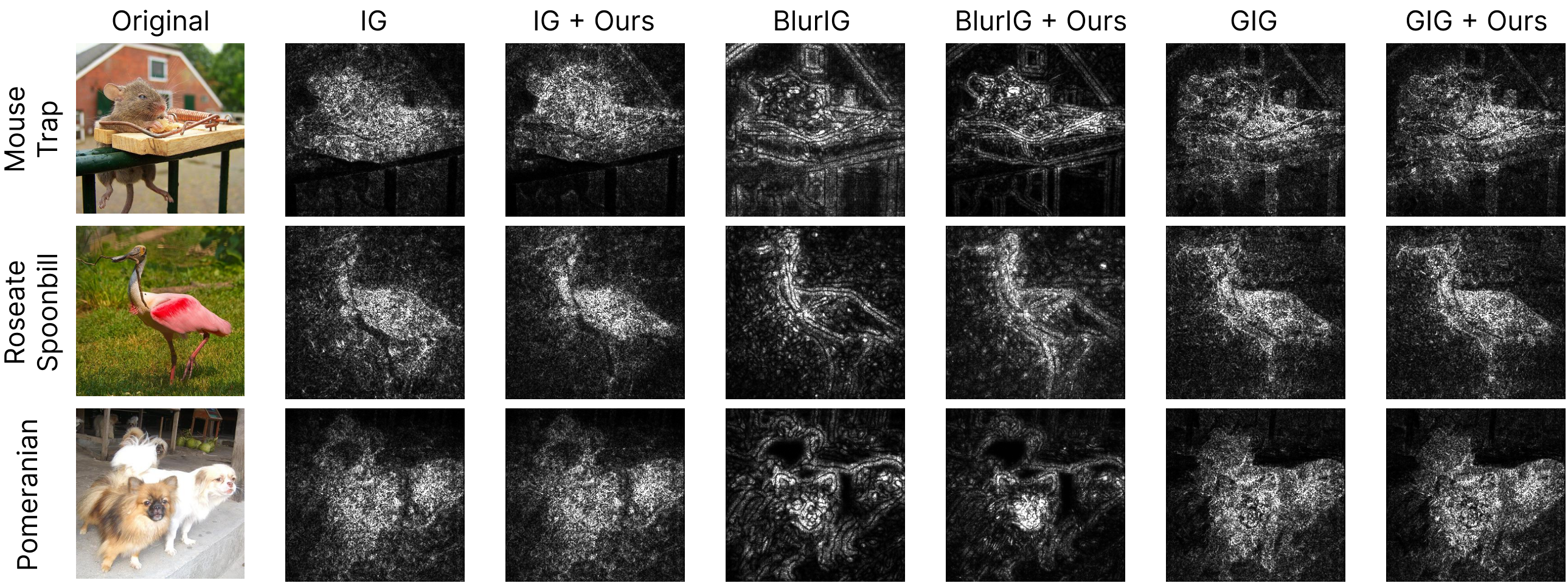
- Riemann Sum Optimization for Accurate Integrated Gradients ComputationShree Singhi* and Swadesh Swain*In NeurIPS 2024 Workshop on Interpretable AI: Past, Present and Future, Dec 2024
Integrated Gradients (IG) is a widely used algorithm for attributing the outputs of a deep neural network to its input features. Due to the absence of closed-form integrals for deep learning models, inaccurate Riemann Sum approximations are used to calculate IG. This often introduces undesirable errors in the form of high levels of noise, leading to false insights in the model’s decision-making process. We introduce a framework, RiemannOpt, that minimizes these errors by optimizing the sample point selection for the Riemann Sum. Our algorithm is highly versatile and applicable to IG as well as its derivatives like Blur IG and Guided IG. RiemannOpt achieves up to 20% improvement in Insertion Scores. Additionally, it enables its users to curtail computational costs by up to four folds, thereby making it highly functional for constrained environments.
@inproceedings{swain2024riemann, title = {Riemann Sum Optimization for Accurate Integrated Gradients Computation}, author = {Singhi, Shree and Swain, Swadesh}, booktitle = {NeurIPS 2024 Workshop on Interpretable AI: Past, Present and Future}, year = {2024}, month = dec, openreview = {https://openreview.net/forum?id=RUictASiLY#discussion}, }